The AdaptRM framework was mainly enabled by adaptive pooling and convolutional neural networks. The model architecture is stated as follows. First, the input sequence is converted to a matrix via one-hot encoding. Repeated standard convolutional blocks are implemented to exploit useful sequence features through learning. Each block contains a convolutional layer, a Dropout function and a PReLU activation function. Two convolution blocks before the adaptive pooling layer aim to extract local information, while the two convolution blocks after that aim to extract general information. The adaptive pooling reduces the amount of data fed into the downstream portion of CNNs, generates vectors of the same size without manually setting polling kernel or stride, and demonstrates a good generalization ability for processing sequences with varying lengths. A linear classifier is placed at last, generating a vector of length T. Each element in it suggests the probability of each assigned task.
The AdaptRM Model
The pooling function can play an important role in a model. It usually aims to capture the essential behavior of input information, reduce the amount of data passed into the subsequent neural networks and increase model generalization ability. In adaptive pooling, the output size is fixed no matter the length of its input layer. The stride and kernel sizes are automatically calculated to adapt to the output size. Therefore, when the input sequences are of varying sizes, each spatial bin being processed is proportional to the input size. The output vector maintains the spatial information of the previous layer well.
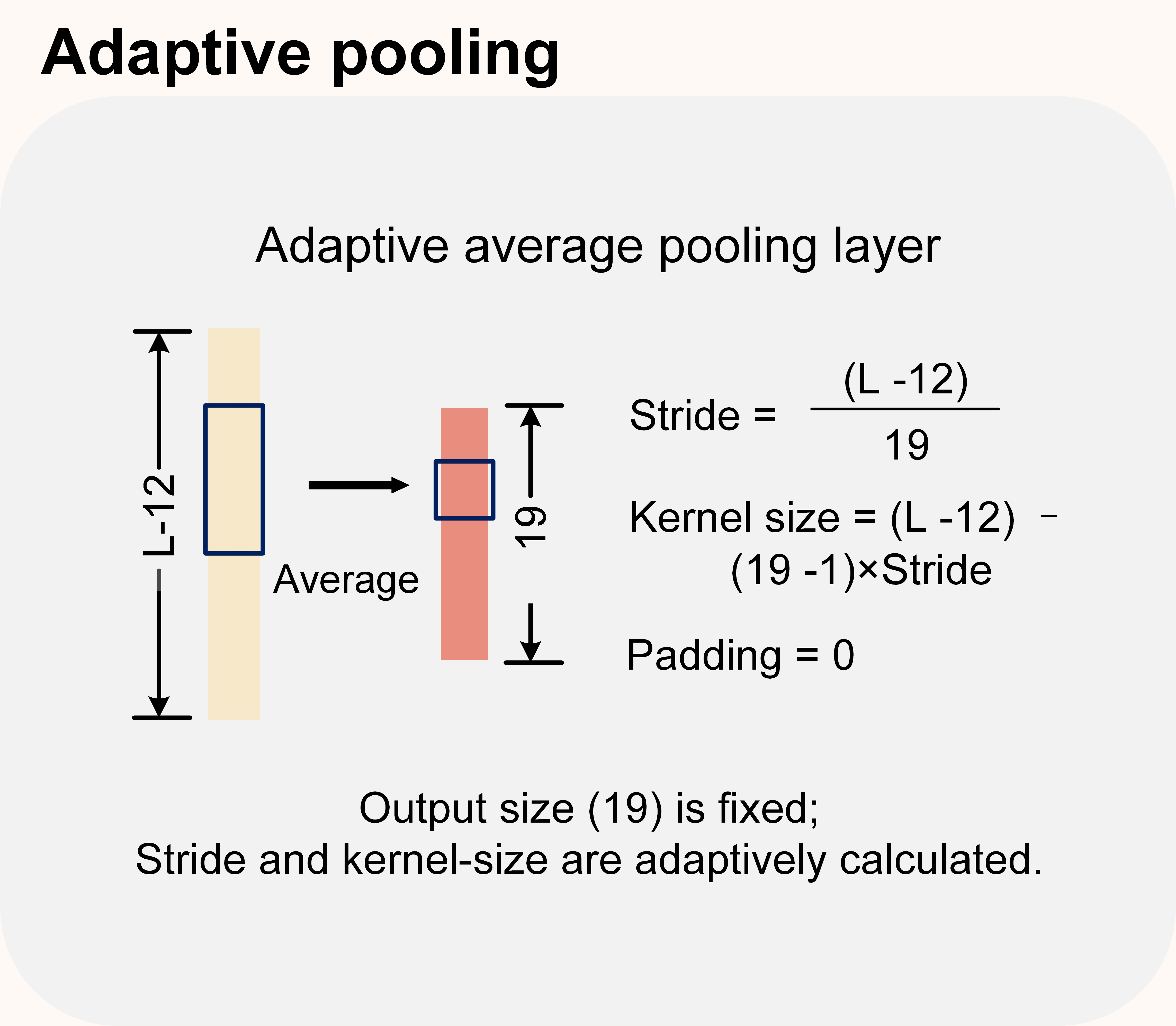
A multi-tasking learning is conducted using AdaptRM, allowing learning several tasks simultaneously so that each task can help all other tasks, effectively avoiding potential overfitting during model training.